[유니코드] 한글 음절과 자모의 영역/주소 - Unicode Hangul Code Point Map
한글 자모 (Hangul Jamo)
한글 초성 ㄱ: 1100
~
한글 종성, 여린히읗:11F9
※ 여린히읗(된이응)은, "ㅎ"에서 맨 위의 점이 없는 것입니다. 즉, 수평선 밑에 동그라미 하나가 있는 모양입니다.
* 한글 호환 자모 (Hangul Compatibility Jamo)
ㄱ: 3131
~
아래아 이: 318E
※ "아래아 이"는 현대 한글의 "이"와 같지만, 이응 대신에 아래아가 있습니다. 즉, 동그라미 대신에 점이 한 개 찍혀 있습니다.
※ 키보드로 한글 자모(ㄱㄴㄷㄹ, ㅏㅑㅓㅕ)를 입력할 때 이 영역이 사용됩니다.
* 한글 음절 (Hangul Syllables)
가: AC00
~
힣: D7A3
※ 가장 중요한 한글 영역입니다. 현대 한글 낱자 11172자가 모두 들어 있습니다.
한글 반각 자모 (Halfwidth Jamo / Halfwidth Hangul variants)
(반각) ㄱ: FFA1
~
(반각) ㅣ: FFDC
※ 위의, "ㅣ" 는, 숫자1이나, 알파벳l이 아니라, 한글 모음 "이"입니다.
※ 이 부분은 쓰이지 않는 것 같습니다.
유니코드에 한글 자모들이 중복되어 있는데, 실제로 사용되는 것은 "한글 호환 자모 (Hangul Compatibility Jamo)"였습니다. uniview.pl 유틸리티로, 실제 한글 자모들의 코드 포인트를 알아본 결과입니다:
3131:ㄱ
3134:ㄴ
3137:ㄷ
3139:ㄹ
3141:ㅁ
3142:ㅂ
3145:ㅅ
3147:ㅇ
3148:ㅈ
314A:ㅊ
314B:ㅋ
314C:ㅌ
314D:ㅍ
314E:ㅎ
314F:ㅏ
3151:ㅑ
3153:ㅓ
3155:ㅕ
3157:ㅗ
315B:ㅛ
315C:ㅜ
3160:ㅠ
3161:ㅡ
3163:ㅣ
AC00:가
D7A3:힣
Code 128 Specification
CODE 128 allows the full ASCII 128 character set to be encoded. By using 4 different bar and space widths it achieves a more compact symbol than would be possible using the older binary (Two bar/space widths) barcode symbologies.
Code 128 may be scanned bidirectionally and there is no restriction on the number of characters allowed in each symbol. There will however be a practical limit determined by the physical size of the resulting barcode and the scanning equipment.
Code 128 has three different character sets defined in the table below as Code Set A, Code Set B and Code Set C. Any of these codes may be selected by appropriate selection of start character. Special 'shift' characters in each Code Set enable an alternative Code Set to be substituted during the scanning process. In this way the physical size of symbol may be minimised by pseudo intelligent algorithms in printing software like Barcode Mill. If the data consists only of numeric data then Code Set C provides twice the packing density of Code Sets A and B. Each code set has one or more characters reserved for special functions.
The Code 128 Specification requires the inclusion of a check digit. The barcode symbol structure consists of...
- A quiet zone, or white space to the left of the bars
- Start character
- A variable number of data characters
- Check digit
- Stop character
- A quiet zone or white space to the right of the bars
The quiet zone should be at least ten times the width of the narrowest bar/space element.
Each character in the barcode symbol is composed of three bars and three spaces. (The stop character has four bars and three spaces as the final symbol will always have a final (extra) bar.)
Each bar or space can be one of four different unit widths. The narrowest possible bar or space will thus be one quarter the width of the widest. The table holds the bar/space widths for all the Code 128 character set. Notice that the sum of the barwidths in any character is always even, and the sum of the space widths is odd. The first column in the table,'The Value', is the value used to calculate the check digit.
The Code 128 specification allows for Human readable information to be printed anywhere outside of the symbol area.
Check Digit Calculation
The check digit is a Modulus 103 checksum. It is calculated by summing the start code 'value' to the products of each character's 'value' multiplied by its position in the barcode string. The left most character is position 1. The sum of the start code value and the products is divided by 103. The remainder is the check digits 'value'. Our Barcode Mill software calculates the check digit for you.
Example... To calculate the check digit for the barcode data string 'Code 128'
Value Total
===== =====
Start Code B 104 104
Position 1 C 35 1 x 35 = 35
Position 2 o 79 2 x 79 = 158
Position 3 d 68 3 x 68 = 204
Position 4 e 69 4 x 69 = 276
Position 5 0 5 x 0 = 0
Position 6 1 17 6 x 17 = 102
Position 7 2 18 7 x 18 = 126
Position 8 8 24 8 x 24 = 192
=====
1197
=====
1197/103 = 11 remainder 64
The check digit is the character from the table with value 64
Code 128 Barcode Table
| Value | Code Set A | Code Set B | Code Set C | Bar/Space Pattern B S B S B S |
|---|---|---|---|---|
| 0 | SP | SP | 00 | 2 1 2 2 2 2 |
| 1 | ! | ! | 01 | 2 2 2 1 2 2 |
| 2 | " | " | 02 | 2 2 2 2 2 1 |
| 3 | # | # | 03 | 1 2 1 2 2 3 |
| 4 | $ | $ | 04 | 1 2 1 3 2 2 |
| 5 | % | % | 05 | 1 3 1 2 2 2 |
| 6 | & | & | 06 | 1 2 2 2 1 3 |
| 7 | ' | ' | 07 | 1 2 2 3 1 2 |
| 8 | ( | ( | 08 | 1 3 2 2 1 2 |
| 9 | ) | ) | 09 | 2 2 1 2 1 3 |
| 10 | * | * | 10 | 2 2 1 3 1 2 |
| 11 | + | + | 11 | 2 3 1 2 1 2 |
| 12 | , | , | 12 | 1 1 2 2 3 2 |
| 13 | - | - | 13 | 1 2 2 1 3 2 |
| 14 | . | . | 14 | 1 2 2 2 3 1 |
| 15 | / | / | 15 | 1 1 3 2 2 2 |
| 16 | 0 | 0 | 16 | 1 2 3 1 2 2 |
| 17 | 1 | 1 | 17 | 1 2 3 2 2 1 |
| 18 | 2 | 2 | 18 | 2 2 3 2 1 1 |
| 19 | 3 | 3 | 19 | 2 2 1 1 3 2 |
| 20 | 4 | 4 | 20 | 2 2 1 2 3 1 |
| 21 | 5 | 5 | 21 | 2 1 3 2 1 2 |
| 22 | 6 | 6 | 22 | 2 2 3 1 1 2 |
| 23 | 7 | 7 | 23 | 3 1 2 1 3 1 |
| 24 | 8 | 8 | 24 | 3 1 1 2 2 2 |
| 25 | 9 | 9 | 25 | 3 2 1 1 2 2 |
| 26 | : | : | 26 | 3 2 1 2 2 1 |
| 27 | ; | ; | 27 | 3 1 2 2 1 2 |
| 28 | < | < | 28 | 3 2 2 1 1 2 |
| 29 | = | = | 29 | 3 2 2 2 1 1 |
| 30 | > | > | 30 | 2 1 2 1 2 3 |
| 31 | ? | ? | 31 | 2 1 2 3 2 1 |
| 32 | @ | @ | 32 | 2 3 2 1 2 1 |
| 33 | A | A | 33 | 1 1 1 3 2 3 |
| 34 | B | B | 34 | 1 3 1 1 2 3 |
| 35 | C | C | 35 | 1 3 1 3 2 1 |
| 36 | D | D | 36 | 1 1 2 3 1 3 |
| 37 | E | E | 37 | 1 3 2 1 1 3 |
| 38 | F | F | 38 | 1 3 2 3 1 1 |
| 39 | G | G | 39 | 2 1 1 3 1 3 |
| 40 | H | H | 40 | 2 3 1 1 1 3 |
| 41 | I | I | 41 | 2 3 1 3 1 1 |
| 42 | J | J | 42 | 1 1 2 1 3 3 |
| 43 | K | K | 43 | 1 1 2 3 3 1 |
| 44 | L | L | 44 | 1 3 2 1 3 1 |
| 45 | M | M | 45 | 1 1 3 1 2 3 |
| 46 | N | N | 46 | 1 1 3 3 2 1 |
| 47 | O | O | 47 | 1 3 3 1 2 1 |
| 48 | P | P | 48 | 3 1 3 1 2 1 |
| 49 | Q | Q | 49 | 2 1 1 3 3 1 |
| 50 | R | R | 50 | 2 3 1 1 3 1 |
| 51 | S | S | 51 | 2 1 3 1 1 3 |
| 52 | T | T | 52 | 2 1 3 3 1 1 |
| 53 | U | U | 53 | 2 1 3 1 3 1 |
| 54 | V | V | 54 | 3 1 1 1 2 3 |
| 55 | W | W | 55 | 3 1 1 3 2 1 |
| 56 | X | X | 56 | 3 3 1 1 2 1 |
| 57 | Y | Y | 57 | 3 1 2 1 1 3 |
| 58 | Z | Z | 58 | 3 1 2 3 1 1 |
| 59 | [ | [ | 59 | 3 3 2 1 1 1 |
| 60 | \ | \ | 60 | 3 1 4 1 1 1 |
| 61 | ] | ] | 61 | 2 2 1 4 1 1 |
| 62 | ^ | ^ | 62 | 4 3 1 1 1 1 |
| 63 | _ | _ | 63 | 1 1 1 2 2 4 |
| 64 | NUL | ` | 64 | 1 1 1 4 2 2 |
| 65 | SOH | a | 65 | 1 2 1 1 2 4 |
| 66 | STX | b | 66 | 1 2 1 4 2 1 |
| 67 | ETX | c | 67 | 1 4 1 1 2 2 |
| 68 | EOT | d | 68 | 1 4 1 2 2 1 |
| 69 | ENQ | e | 69 | 1 1 2 2 1 4 |
| 70 | ACK | f | 70 | 1 1 2 4 1 2 |
| 71 | BEL | g | 71 | 1 2 2 1 1 4 |
| 72 | BS | h | 72 | 1 2 2 4 1 1 |
| 73 | HT | i | 73 | 1 4 2 1 1 2 |
| 74 | LF | j | 74 | 1 4 2 2 1 1 |
| 75 | VT | k | 75 | 2 4 1 2 1 1 |
| 76 | FF | I | 76 | 2 2 1 1 1 4 |
| 77 | CR | m | 77 | 4 1 3 1 1 1 |
| 78 | SO | n | 78 | 2 4 1 1 1 2 |
| 79 | SI | o | 79 | 1 3 4 1 1 1 |
| 80 | DLE | p | 80 | 1 1 1 2 4 2 |
| 81 | DC1 | q | 81 | 1 2 1 1 4 2 |
| 82 | DC2 | r | 82 | 1 2 1 2 4 1 |
| 83 | DC3 | s | 83 | 1 1 4 2 1 2 |
| 84 | DC4 | t | 84 | 1 2 4 1 1 2 |
| 85 | NAK | u | 85 | 1 2 4 2 1 1 |
| 86 | SYN | v | 86 | 4 1 1 2 1 2 |
| 87 | ETB | w | 87 | 4 2 1 1 1 2 |
| 88 | CAN | x | 88 | 4 2 1 2 1 1 |
| 89 | EM | y | 89 | 2 1 2 1 4 1 |
| 90 | SUB | z | 90 | 2 1 4 1 2 1 |
| 91 | ESC | { | 91 | 4 1 2 1 2 1 |
| 92 | FS | | | 92 | 1 1 1 1 4 3 |
| 93 | GS | } | 93 | 1 1 1 3 4 1 |
| 94 | RS | ~ | 94 | 1 3 1 1 4 1 |
| 95 | US | DEL | 95 | 1 1 4 1 1 3 |
| 96 | FNC 3 | FNC 3 | 96 | 1 1 4 3 1 1 |
| 97 | FNC 2 | FNC 2 | 97 | 4 1 1 1 1 3 |
| 98 | SHIFT | SHIFT | 98 | 4 1 1 3 1 1 |
| 99 | CODE C | CODE C | 99 | 1 1 3 1 4 1 |
| 100 | CODE B | FNC 4 | CODE B | 1 1 4 1 3 1 |
| 101 | FNC 4 | CODE A | CODE A | 3 1 1 1 4 1 |
| 102 | FNC 1 | FNC 1 | FNC 1 | 4 1 1 1 3 1 |
| 103 | Start A | Start A | Start A | 2 1 1 4 1 2 |
| 104 | Start B | Start B | Start B | 2 1 1 2 1 4 |
| 105 | Start C | Start C | Start C | 2 1 1 2 3 2 |
| 106 | Stop | Stop | Stop | 2 3 3 1 1 1 2 |
p.s 2009년 5월 8일 추가 수정함.
 table_desc.sql
table_desc.sql SQL2005_Sys_Views.pdf
SQL2005_Sys_Views.pdf한글 메뉴가 안 나와서 비스타의 한글 관련 폴더(ko-kr)를 복사해 왔더니 한글 메뉴가 나오더군요.
웹 사이트 등록 정보에 asp.net 탭이 없고, 웹 서비스 확장에 ASP.NET v2.0.50727 항목이 없는 경우,
아래와 같이 해결하면 된다.
Visual Studio 2008 or 2005 명령 프롬프트를 실행한 후에,
aspnet_regiis -i 를 실행하면 된다.
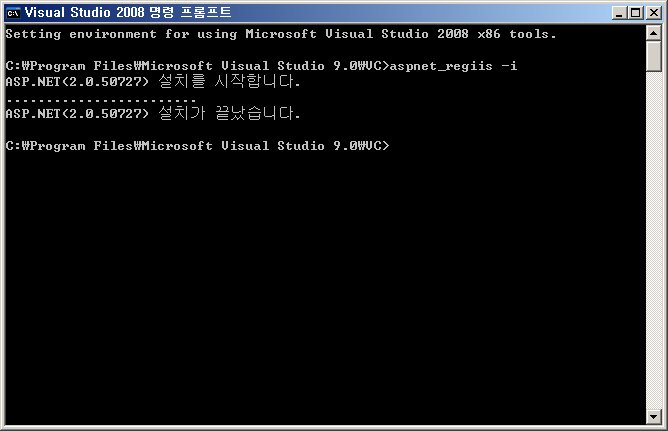
대충 아래와 같이 서버의 세션 상태에 대한 에러 메시지가 나타나면,
iis가 운영 중인 웹 서버의 관리도구 - 서비스 에서 "ASP.NET State Service" 항목을 시작을 눌러서 서비스 실행 상태로 만들어 준다.
error
'/ECMobileMain' 응용 프로그램에 서버 오류가 있습니다.
|
현재 웹 요청을 실행하는 동안 처리되지 않은 예외가 생성되었습니다. 아래의 예외 스택 추적을 사용하여 예외의 원인 및 위치 정보를 확인할 수 있습니다. |
스택 추적:
|
버전 정보: Microsoft .NET Framework 버전:2.0.50727.3082; ASP.NET 버전:2.0.50727.3082
해결 방안

출처 : http://cutecars.tistory.com/category
정규 표현식은 책으로도 1권 될 정도로 분량도 많고 복잡하기도 하고 나에겐 매우 어렵다..ㅡ,.ㅡ;
그래서 네이년한테 물어봤더니 쫘~~~~악~~ 그것도 한글로 나오는데 읽어도 읽어도 당췌 뭔소린지
알수가 없다...ㅡ,.ㅡ;;;; 고로 거창하게는 아니고 그냥 프로젝트하다가 적용한 사례 정도만 나중에 혹시
사용할일이 있지 않을까해서 정리해논다(사실 정리 안됨..ㅡ,.ㅡ;;)
본인은 C, C++이 주 언어지만(그렇다고 절대로!! 잘하는건 아님) C#코드로 구현했기 때문에
개발자답게(?) 고대로 Copy & Paste와 간단한 설명을 남긴다.
참고로 C#인지 닷넷인지뭔지 몰라도 이놈은 정규식을 완벽히 지원한단다.
using System.Text.RegularExpressions
bool IsVaildStr(string strText)
{
string Pattern = @"^[a-zA-Z0-9가-힣]*$";
return Regex.IsMatch(strText, Pattern);
}
간단히 설명하자면 strText의 문자열이 대-소문자 알파벳, 숫자, 한글인지를 체크하는 정규식이다
유저 계정 만들때 사용한 정규식인데 아이디에 특수문자를 사용할수 없게끔하는 식이다
특이하게 한글이 들어간 이유는 모 포탈 사이트에서는(한게임인가로 기억됨...아님 말고...^^)
한글 계정도 지원한다기에 그냥 넣어봤다
자세한 내용은 아래 설명 참조!
※ 정규식 설명
^
입력의 시작 위치를 의미한다. 여러 줄 모드에서는 줄바꿈 뒤도 의미한다
/^A/
"An A"에서 시작 위치 바로 뒤의 A는 일치하지만 마지막의 A는 일치하지 않는다.
^[a-z]
첫 글자는 반드시 소문자 a-z 사이의 문자를 뜻한다
$
입력의 마지막 위치를 의미한다. 여러 줄 모드에서는 줄바꿈 앞도 의미한다.
/a$/
"Cocoa"에서 마지막에 있는 'a'와 일치한다.
[a-z]$
마지막 글자는 반드시 소문자 a-z사이의 문자를 뜻한다
*
* 앞의 문자가 0번 이상 반복됨을 의미한다.
선택 기호: "|" 기호는 여러 식 중에서 하나를 선택한다.
"abc|adc"는 abc라는 문자열과 adc라는 문자열을 모두 포함한다.
묶기 기호: (와 )로 여러 식을 하나로 묶을 수 있다.
"abc|adc"와 "a(b|d)c"는 같은 의미를 가진다.
[] : [과 ] 사이의 문자 중 하나를 선택한다. "|"를 여러 개 쓴 것과 같은 의미를 가진다.
[abc]d는 ad, bd, cd를 뜻한다. 또한, "-" 기호와 함께 쓰면 문자의 범위를 지정할 수 있다.
[a-z]는 a부터 z까지 중 하나, [1-9]는 1부터 9까지 중의 하나를 뜻한다.
[^] : [^과 ] 사이의 문자를 제외한 나머지 하나를 선택한다.
[^abc]d는 ad, bd, cd는 포함하지 않고 ed, fd 등을 포함한다.
[^a-z]는 알파벳 소문자로 시작하지 않는 모든 문자를 나타낸다.
※ POSIX 문자 그룹(character Classes)
Dos를 사용하던 시절에는 *, !, ?, <>, [] 같은 wildcard 문자를 사용하여 다양한 작업을 했었습니다.
이 방식은 지금도 unix 계열에서는 사랑받는 방식입니다.
그리고 현재도 콘솔에서 프로그램 뒤에 파라미터를 넣는 방식은 널리 사용되고 있습니다.
정규 표현식은 이런 정의된 문자를 사용해서 패턴을 만들고 그 패턴을 이용해서 원하는 문자를 가져오거나 바꾸는 데 사용되는 방식입니다.
C#에서도 이런 정규 표현식을 작업하기 쉽도록 지원해 줍니다. 그럼 정규 표현식을 지원하는 클래스 들을 알아보겠습니다.
일단 정규 표현식 관련 클래스들은 System.Text.RegularExpressions 에 있습니다.
그리고 System.Text.RegularExpressions 에는 Regex 클래스가 존재합니다.
이 Regex 클래스에는 정적 메서드가 여러 개 포합되어 있어서 Regex 개체를 명시적으로 만들지 않고도 정규식을 사용할 수 있습니다.한번 사용한 다음 소멸시킨다는 점에서 정적 메서드를 사용하는 것은 Regex 개체를 만드는 것과 같습니다. Regex 클래스 자체는 스레드로부터 안전하며 읽기 전용으로, 변경할 수 없습니다. 즉, Regex 개체는 모든 스레드에서 만들어질 수 있고 또한 스레드 간에 공유될 수 있으며 관련 메서드는 전역 상태에 전형 영향을 주지 않으면서 모든 스레드에 대해 호출될 수 있습니다. 그러나 Regex 에서 반환하는 Match 및 MatchCollection 과 같은 결과 개체는 단일 스레드에서만 사용해야 합니다.
Regex 클래스에서 자주 사용되는 메서드들은 다음과 같습니다.
l IsMatch(string) - 정규식이 입력 문자열에서 일치하는 항목을 찾을 것인지 여부를 나타냅니다.
l Match(string) - 입력 문자열에 정규식이 있는지 검사하고 정확한 결과를 단일 Match 개체로 반환합니다.
l Matches(string) - Match를 여러 번 호출한 것처럼 입력 문자열에 있는 정규식을 모두 검색하고 성공적인 일치 항목을 모두 반환합니다.
l Replace(pattern, string) - 정규식에 의해 정의된 문자 패턴이 발견되면 지정된 대체 문자열로 모두 바꿉니다.
l Split(string, pattern) - 정규식 일치에 의해 정의된 위치에서 부분 문자열로 이루어진 배열로 입력 문자열을 분할합니다.
이제 간단한 예제들을 보여 드리겠습니다.
언제나 그러하듯 아래 예제들은 제가 msdn 및 기타 사이트 들에서 긁어온 것들을 살짝 변경하였습니다.
IsMatch() 와 Match() 메서드의 사용법을 알수 있는 예제입니다.
(http://msdn.microsoft.com/ko-kr/library/system.text.regularexpressions.regex_members(VS.80).aspx)
|
using System; using System.Text.RegularExpressions; public class Test { public static void Main() { // 정규 표현식을 정의합니다. Regex rx = new Regex(@"^-?\d+(\.\d{2})?$"); // 입력될 스트링을 정의합니다. string[] tests = { "-42", "19.99", "0.001", "100 USD" }; // 테스트 코드입니다. foreach (string test in tests) { if (rx.IsMatch(test)) Console.WriteLine("{0} is a currency value.", test); else Console.WriteLine("{0} is not a currency value.", test); } Console.ReadLine(); } } |

이번에도 IsMatch() 와 Match() 메서드의 사용법을 알수 있는 예제입니다. (http://www.mikesdotnetting.com/Article.aspx?ArticleID=50)
|
using System; using System.Text.RegularExpressions; namespace TestCode03 { class Program { static void Main(string[] args) { string input = "A12"; //Regex 개체를 생성하는 예제입니다. //@"[a-z]\d": 알파벳이 나온 후 integer 형이 나옵니다. //RegexOptions.IgnoreCase: 대소문자를 구문하지 않는 옵션입니다. Regex re = new Regex(@"[a-z]\d", RegexOptions.IgnoreCase); Match m = re.Match(input); if (re.IsMatch(input)) { Console.Write(m.Value + "\n"); } Console.Write(re.IsMatch(input) + "\n"); //정정 메소드인 Regex를 생성하지 않는 예제입니다. Match m2 = Regex.Match(input, @"[a-z]\d"); if (Regex.IsMatch(input, @"[a-z]\d")) { Console.Write(m2.Value + "\n"); } Console.Write(Regex.IsMatch(input, @"[a-z]\d") + "\n"); Console.ReadLine(); } } } |

MatchCollection 클래스와 Match 클래스의 사용법을 알수 있는 예제입니다.
(http://msdn.microsoft.com/ko-kr/library/system.text.regularexpressions.regex_members(VS.80).aspx)
|
using System; using System.Text.RegularExpressions; public class Test { public static void Main() { // 반복을 위한 정규 표현식입니다. Regex rx = new Regex(@"\b(?<word>\w+)\s+(\k<word>)\b", RegexOptions.Compiled | RegexOptions.IgnoreCase); // 입력되는 문자열입니다. string text = "The the quick brown fox fox jumped over the lazy dog dog."; // 일치하는 문자열을 찾습니다. MatchCollection matches = rx.Matches(text); // 표현식과 일치하는 문자열의 갯수를 나타냅니다. Console.WriteLine("{0} matches found.", matches.Count); // 일치한 문자열을 표시합니다. foreach (Match match in matches) { string word = match.Groups["word"].Value; int index = match.Index; Console.WriteLine("{0} repeated at position {1}", word, index); } Console.ReadLine(); } } |

MatchCollection 클래스와 Match 클래스의 사용법을 알수 있는 예제입니다.
(http://www.mikesdotnetting.com/Article.aspx?ArticleID=50)
|
using System; using System.Text.RegularExpressions; namespace TestCode04 { class Program { static void Main(string[] args) { string input = "A12 B34 C56 D78"; //Regex 개체를 생성합니다. Regex re = new Regex(@"[a-z]\d", RegexOptions.IgnoreCase); MatchCollection mc = re.Matches(input); foreach (Match mt in mc) { Console.Write(mt.ToString() + "\n"); } Console.Write(mc.Count.ToString() + "\n"); //Regex는 정적클래스 이므로 개체를 생성하지 않아도 됩니다. MatchCollection mc2 = Regex.Matches(input, @"[a-z]\d", RegexOptions.IgnoreCase); foreach (Match mt in mc) { Console.Write(mt.ToString() + "\n"); } Console.Write(mc2.Count.ToString() + "\n"); Console.ReadLine(); } } } |

Replace메서드의 사용법을 알수 있는 예제입니다. 알파벳을 “XX”로 변환합니다.
|
using System; using System.Text.RegularExpressions; namespace TestCode05 { class Program { static void Main(string[] args) { string input = @"A12 B34 C56 D78 E12 F34 G56 H78"; //Regex 개체 생성 Regex re = new Regex(@"[a-z]\d", RegexOptions.IgnoreCase); string newString = re.Replace(input, "XX"); Console.Write(newString); //Regex 개체를생성하지 않아도 됩니다. string newString2 = Regex.Replace(input, @"[A-Z]\d", "XX"); Console.Write(newString2); Console.ReadLine(); } } } |

Split메서드의 사용법을 알수 있는 예제입니다. 알파벳을 “XX”로 변환합니다.
|
using System; using System.Text.RegularExpressions; namespace TestCode06 { class Program { static void Main(string[] args) { string input = "AB1 DE2 FG3 HI4 JK5 LM6 NO7 PQ8 RS9"; //Regex 개체 생성 Regex re = new Regex(@"\s"); string[] parts = re.Split(input); foreach (string part in parts) { Console.Write(part + "\n"); } //Regex 개체를생성하지 않아도 됩니다. 스페이스를 기준으로 문자열을 분할합니다. string[] parts2 = Regex.Split(input, @"\s"); foreach (string part2 in parts2) { Console.Write(part2 + "\n"); } Console.ReadLine(); } } } |

End.
유니코드도 버전별로 지원하는 문자가 틀리군...
가끔 DB에 저장된 데이터가 브라우저에 표시될 때 표시할 수 없는 경우가 있다.
이 경우에는 해당 클라이언트의 유니코드 버전이 낮아서 그런 것 같다.
해결 방안은 정규식을 이용해서 해당 유니코드를 치환하거나 alert 창을 띄우거나 해야겠다.
상세한 해결 방안은 나중에...
 Prev
Prev

 Rss Feed
Rss Feed